

Problem Description / Requirement
This example comes from a software application that has strictly implemented its relational model. The challenge uses two tables linked by referential integrity.
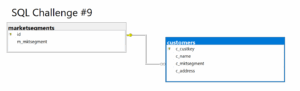
The [dbo].[marketsegments] table serves as a reference table for the real names of a customer’s market segment. In the [dbo].[customers] table, the [id] of the reference table is stored in the [c_mktsegment] attribute, allowing the real name to be output using a JOIN.
The following query was identified as a problem because it does not scale when searching for a market segment and allocates too much or too little memory for the sorting process, depending on the number of records found:
SELECT c.c_custkey,
c.c_name,
m.m_mktsegment,
c.c_address
FROM dbo.customers AS c
INNER JOIN dbo.marketsegments AS m
ON (c.c_mktsegment = m.id)
WHERE m.m_mktsegment = '<marketsegment>'
ORDER BY
c.c_name ASC
Problem
The problem with the query is that searching for “AUTOMOBIL” uses too much memory for the sorting operation, while searching for “BUILDING” causes a SORT SPILL, which can lead to significant delays.
Note
Run the query with both parameter values and observe the warnings on the relational operators.
- The query with the “AUTOMOBILE” parameter displays a warning that too much memory is being used.
- The query with the “BUILDING” parameter displays a warning that too little memory was requested and data in TEMPDB needs to be sorted.
Challenge
The query must generate an ideal execution plan, regardless of the parameter value to be searched, that requests the resources depending on the expected data.
- The query itself may not be changed or rewritten.
- Custom indexes/statistics may be used.
- User database properties may be reconfigured.
Condition
- none. You can do all to improve the query (adding indexes, tables, partitions, …)
Technical Information
The challenge #9 creates two tables with the following structure/data
- [dbo].[customers] with 100,000 rows
- primary key: pk_customers (c_custkey)
- nonclustered index: nix_customers_c_mktsegment (c_mktsegment)
- [dbo].[marketsegments] with 2 rows
- primary key: pk_marketsegments (id)
- Foreign Key Constraint between [dbo].[marketsegments] and [dbo].[customers] (id) -> c_mktsegment
How to start the challenge
When you are connected to the SQL Server instance, run the following commands:
EXECUTE sqlchallenge.dbo.create_challenge 'list'; |
will give you a list of open challenges |
EXECUTE sqlchallenge.dbo.create_challenge 'SQL Challenge #9 - estimates going wrong'; |
will create the challenge for you |
customer expectations
The query should generate an optimal execution plan and consume ideal memory the SORT operator
The query must not be changed because it is generated from the framework of the software
Solution
https://www.sqlchallenges.de/sql-challenge-9-solution/
Connect to Microsoft SQL Server
| SQL Server: | sqlchallenges.germanywestcentral.cloudapp.azure.com |
| Port: | 1433 |
| Version: |
16.0.4165.4
|
| Edition: | Developer Edition |
| Authentication Type: | SQL Server Authentication |
| Login Name: | sqlchallenge |
| Password: | sqlchallenge#2025! |
| Encryption | Mandatory |
| Trust Server Certificate: | True |

During this workshop, you’ll gain the expertise and confidence needed to diagnose and fine-tune slow-performing queries, resulting in improved database responsiveness and end-user satisfaction. Whether you’re an experienced database administrator, developer, or data analyst, this workshop will equip you with the knowledge and practical skills to tackle the most challenging query optimization tasks.

In this workshop, we will cover a wide range of topics and techniques that are essential for modern database developers working with SQL Server. From fundamental concepts to advanced best practices, you’ll gain the knowledge and practical experience needed to excel in your role.
Hi – i know you have posted the solution. But nevertheless i felt the urge to play with it for a bit.
CREATE NONCLUSTERED INDEX asdasd
ON dbo.customers (c_mktsegment, c_name ASC) INCLUDE (c_custkey, c_address)
CREATE UNIQUE NONCLUSTERED INDEX asdasd2 ON dbo.marketsegments (m_mktsegment)
Here i have made the assumption that the m_mktsegment on marketsegments is unique.
This gives you still wrong estimates on customers – but only one row guaranteed from marketsegments.
So we get only one row from marketsegments and a nested loop iterator that consumes data ordered from customers. This eliminates the sort operation. But it still leaves me with bad estimates on customers – so still not an optimal plan.
So in total i get – 2xindex seek and 1xnested loop