
Problem Description / Requirement
Time series queries have always been—and continue to be—a challenge for database developers because they may not scale. This is exactly what happened to a customer who encountered the following problem.
The customer operates in the automotive industry and uses software that logs EVERY activity on the assembly line in so-called telegrams. Each telegram is assigned a start date (begin_ts) and an end date (end_ts). If a disruption occurs on the assembly line, the plant manager and his team need to know exactly what was active at a specific time. This includes processes that began many hours ago (e.g., vehicle painting, shift start, etc.) as well as processes that have just begun in this time window.
It is therefore not just important to know processes that are in the exact time window, but also to provide processes that have already begun or that have begun within the time window and have not yet been completed.
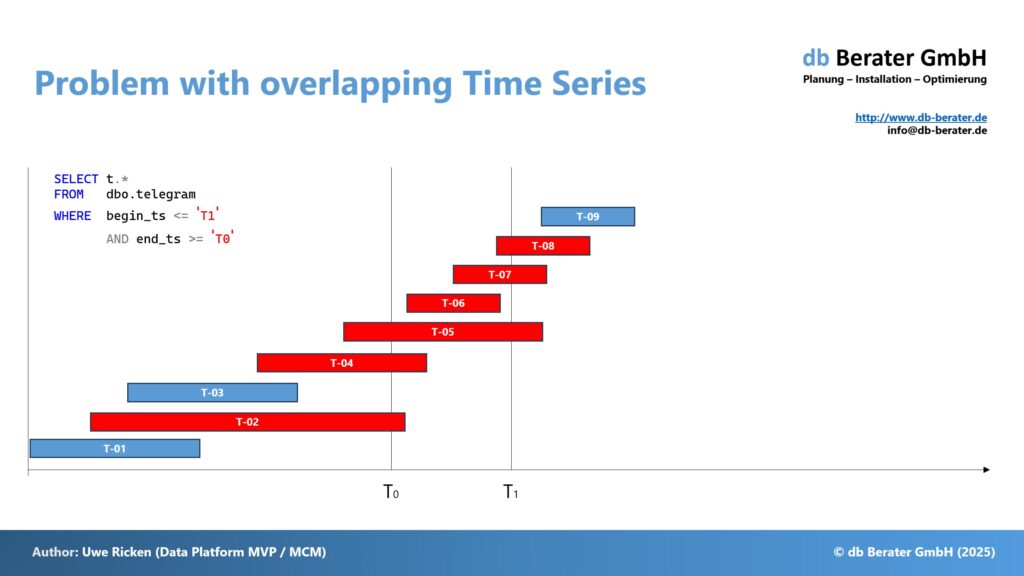
The figure above illustrates the problem of a query with overlapping time periods. If a query is executed with a time period from T0 to T1, not only this time period must be considered, but – technically – the entire table must be considered. While “T-01” and “T-03” are ignored, T-02, T-04, T-05, T-06, T-07, and T-08 must appear in the result set. T-09, in turn, must be ignored because this telegram was created after T1.
Challenge
- The table is called [dbo].[telegram] and contains ~45 mio tuples
- The table has only a Clustered Primary Key on the attribute [id]
- The data are distributed from 2025-05-12 12:00 to 2025-06-11 21:00
- The customer asked us to develop a solution that would always be executed efficiently, regardless of the time frame.
- We are free to use indexes
- We can use additional tables, functions, stored procedures, …
Solution
Basically, there is no such thing as THE solution. Perhaps you, dear reader, have an even better idea for solving the problem.
First, I came across a very interesting series of articles by Itzik Ben Gan, who attempted—unfortunately in my case, in vain—to explain the concept of a “Static Relational Interval Tree,” developed by three researchers (Hans-Peter Kriegel, Marco Pötke, and Thomas Seidl) at the University of Munich. I’m not a mathematician, but a lawyer by education, so I put that solution aside. Nevertheless, the problem was immediately clear to me, and a relational alternative came to mind that doesn’t require such high mathematical requirements: the use of an interval table!
Step 1: Root Cause Analysis
The customer attempts to query the required data using an index that considers the two attributes in the WHERE clause. It is noticeable that the result is sometimes evaluated in a few milliseconds, while at other times it takes 30 seconds or more to execute. The following script first creates an index for the dbo.telegram table and then executes three queries with different timestamps (but always at the same interval!).
/* We create an index on both attributes with the timestamps */
CREATE NONCLUSTERED INDEX telegram_end_ts_begin_ts ON dbo.telegram
(
end_ts,
begin_ts
)
WITH
(
DATA_COMPRESSION = PAGE,
SORT_IN_TEMPDB = ON
);
GO
Note
For the purpose of describing the problem, the order in which the attributes are used in the index is initially irrelevant. The problem arises from the position of the data within the index!
/* Beginning of the table */
SELECT id, [t_status], begin_ts, end_ts
FROM dbo.telegram
WHERE begin_ts <= CAST('2025-05-12 14:00' AS DATETIME2(3))
AND end_ts >= CAST('2025-05-12 13:00' AS DATETIME2(3));
GO
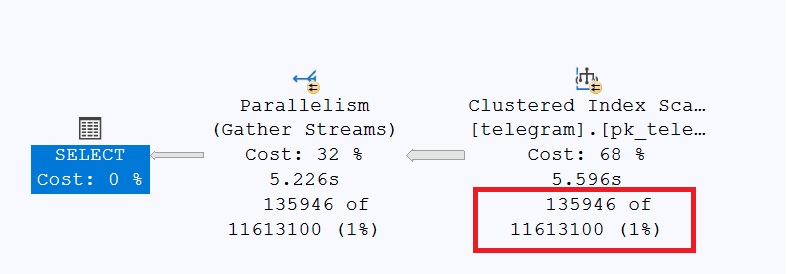
I’ll spare you the further tests, as they also generate the same execution plan. The reason for the FULL SCAN is a misinterpretation of the expected data volume. The NONCLUSTERED index doesn’t cover the [t_status] attribute. Thus, SQL Server would have to use a separate key lookup to retrieve the missing information from the table. Given this situation, you could now try to add the missing attribute to the nonclustered index using INCLUDE. Before considering such steps, you should first test whether the index would work in general. The following query only covers the attributes of the nonclustered index—a separate key lookup is no longer necessary!
/* Beginning of the table */
SELECT id, begin_ts, end_ts
FROM dbo.telegram
WHERE begin_ts <= CAST('2025-05-12 13:58:41.489' AS DATETIME2(3))
AND end_ts >= CAST('2025-05-12 13:00' AS DATETIME2(3))
GO
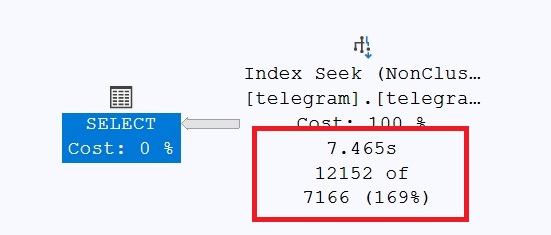
/* Middle of the table */
SELECT id, begin_ts, end_ts
FROM dbo.telegram
WHERE begin_ts <= CAST('2025-05-26 14:00' AS DATETIME2(3))
AND end_ts >= CAST('2025-05-26 13:00' AS DATETIME2(3))
GO
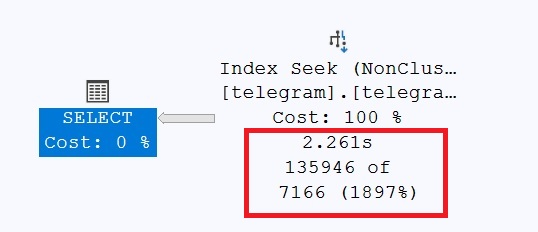
/* Very end of the table */
SELECT id, [t_status], begin_ts, end_ts
FROM dbo.telegram
WHERE begin_ts <= CAST('2025-06-11 14:00' AS DATETIME2(3))
AND end_ts >= CAST('2025-06-11 13:00' AS DATETIME2(3))
GO
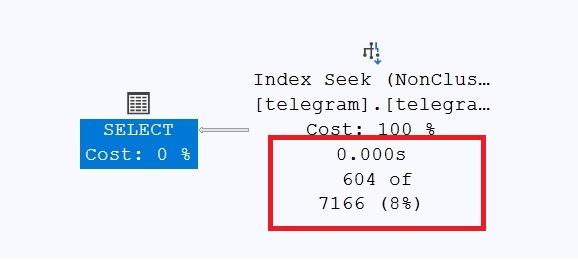
Why are the estimates be off?
- SQL Server builds statistics on column values, but those stats may not capture millisecond-level precision. If the data distribution is tight or skewed, the optimizer might misjudge how many rows fall within the range.
- The query uses a range filter (begin_ts <= … AND end_ts >= …), which is harder to estimate than equality. The optimizer has to guess how many rows overlap that time window — and overlapping intervals are notoriously tricky to model.
- Because the index is on (end_ts, begin_ts), SQL Server may not use it efficiently unless the query filters match the index order.
This task presents two extreme challenges for Microsoft SQL Server. First, timestamps are stored that are accurate to the millisecond. This prevents Microsoft SQL Server from creating accurate statistics. There are simply too many different values. Furthermore, the query uses an index that binds both attributes used as criteria in the query. Only the first attribute in an index can be used for a targeted search, the second attribute must always be filtered!
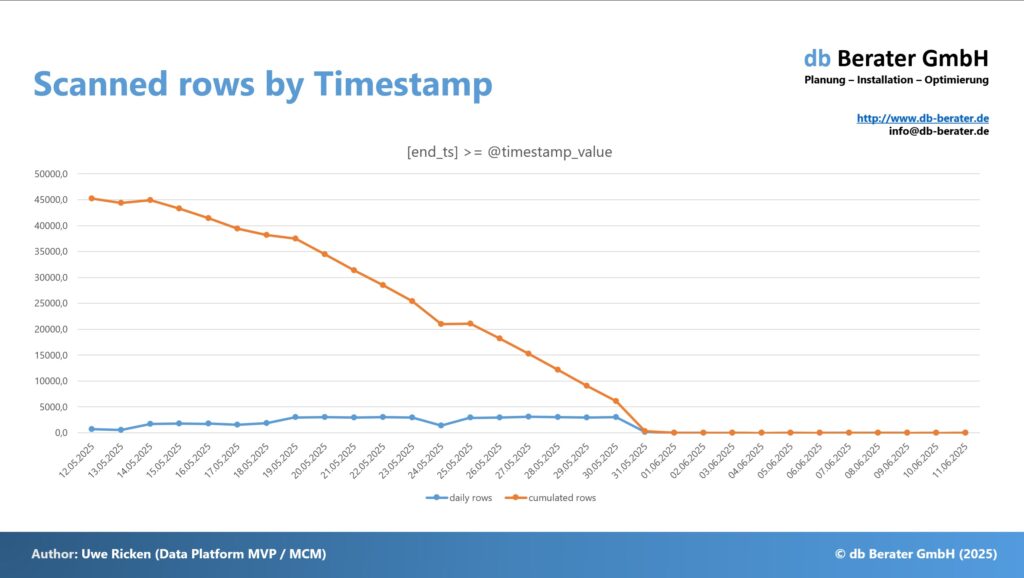
Pay attention to the date as a parameter. The further the value points into the past, the more records need to be checked in the index. As the values point to the present, fewer records will be considered by the index. Within the records to be considered, you must also filter by [begin_ts].
Step 2: Finding an appropriate solution
Two significant problems need to be solved. First, the composite index problem must be resolved, as it is inadequate for the task at hand. Furthermore, it must be ensured that the estimates are as stable as possible.
Problem of Composite Index
My solution is based on storing the time span between [begin_ts] and [end_ts] in an additional table at predefined intervals. For example, if a time span is from 10:00 to 11:35, the additional table stores multiple records with fixed intervals of x minutes for an [id]. This eliminates the need for a composite index, and allows you to search for a time interval in one attribute instead of a composition of multiple attributes. Please note that you get more rows as smaller the interval is. I’ve done it with an interval of 15 mins.
/* Creation of a table for the storage of the intervals */
CREATE TABLE dbo.telegram_interval
(
id BIGINT NOT NULL,
[timestamp] DATETIME2(3) NOT NULL,
CONSTRAINT pk_telegram_interval PRIMARY KEY CLUSTERED
(
timestamp,
id
)
WITH (DATA_COMPRESSION = PAGE)
);
GO
/* Creation of a helper function to travers the time range into intervals */
CREATE OR ALTER FUNCTION dbo.get_telegram_intervals
(
@begin_ts DATETIME2(3),
@end_ts DATETIME2(3),
@interval_min SMALLINT = 15
)
RETURNS TABLE
AS
RETURN
(
WITH l
AS
(
SELECT DATE_BUCKET(MINUTE, @interval_min, @begin_ts) AS [timestamp]
UNION ALL
SELECT DATEADD(MINUTE, @interval_min, [timestamp])
FROM l
WHERE [timestamp] < @end_ts
)
SELECT [timestamp] FROM l
);
GO
/*
Filling the interval table with intervals from dbo.telegram
Note: This batch processing is necessary because of the limited resources of the demo machine
*/
DECLARE @start_date DATE = (SELECT MIN(begin_ts) FROM dbo.telegram);
DECLARE @row_count INT = 1;
WHILE @row_count > 0
BEGIN
INSERT INTO dbo.telegram_interval WITH (TABLOCK)
(id, [timestamp])
SELECT t.id,
gti.[timestamp]
FROM dbo.telegram AS t
CROSS APPLY dbo.get_telegram_intervals
(
t.begin_ts,
t.end_ts,
15
) AS gti
WHERE begin_ts >= @start_date
AND begin_ts < DATEADD(DAY, 1, @start_date)
OPTION (MAXRECURSION 0);
SET @row_count = @@ROWCOUNT;
SET @start_date = DATEADD(DAY, 1, @start_date);
END
GO
Function for the retrieval of available [id]
For the concept to work, an additional user-defined function must be created that divides the specified time interval into individual intervals and then returns only the [Id] that is within the specified time interval.
/* Creation of a User Defined Function for the list of id */
CREATE OR ALTER FUNCTION dbo.get_interval_id
(
@begin_ts DATETIME2(3),
@end_ts DATETIME2(3)
)
RETURNS @t TABLE (id BIGINT NOT NULL PRIMARY KEY CLUSTERED)
AS
BEGIN
INSERT INTO @t
SELECT DISTINCT id
FROM dbo.telegram_interval
WHERE [timestamp] >= DATE_BUCKET(MINUTE, 15, @begin_ts)
AND [timestamp] <= DATE_BUCKET(MINUTE, 15, @end_ts)
RETURN
END
GO
Once the function is created, the original query can be rewritten. Using the previously created custom function, the index of the interval table can be efficiently searched for the matching [Id].
Note
You may wonder why I am using a Multi Statement Table Valued Function because everyone is telling you that it should be avoid and be replaced by an Inline Function! This statement is generally correct; we usually want a good estimate of the number of rows of data to be returned. However, in this particular case, things are different, as the following examples will show. The problem can only be solved with a multiline table-valued function!
Performance Check of the Solution
For the tests, I use two different time intervals, each starting at the earliest and latest timestamp, and covering an interval of 30 minutes.
/* This statement must run in SQLCMD modus! */
:SETVAR begin_ts "2025-05-12 12:15:00.000"
:SETVAR end_ts "2025-05-12 12:45:00.000"
/* Orignal query */
SELECT t.*
FROM dbo.telegram AS t
WHERE begin_ts <= CAST('$(end_ts)' AS DATETIME2(3))
AND end_ts >= CAST('$(begin_ts)' AS DATETIME2(3))
ORDER BY
id
GO
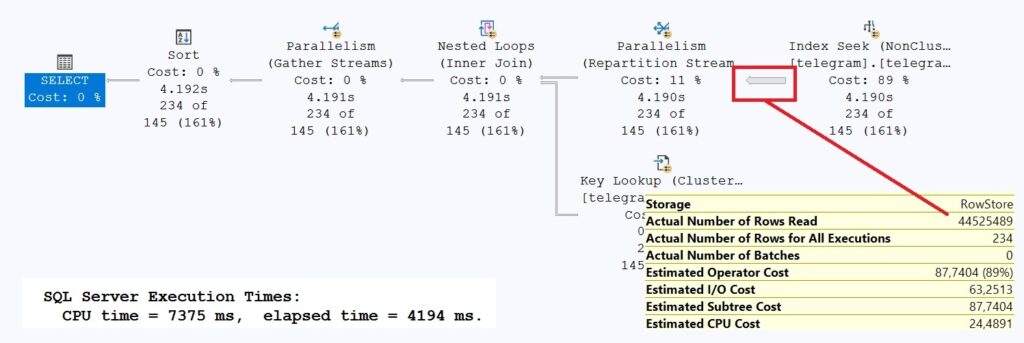
Although this query returned only 234 records, it took over 4 seconds to run. The reason for this runtime behavior is the [telegram_end_ts_begin_ts] index. While the value for end_ts is very close to the beginning of the index, BUT… – the performance killer is begin_ts, because SQL Server needs to find all records in the index whose value in [begin_ts] is greater than the search value. However, since the search value is at the beginning of the index, the entire index must be scanned!
/* This statement must run in SQLCMD modus! */
:SETVAR begin_ts "2025-06-11 12:00:00.000"
:SETVAR end_ts "2025-06-11 13:00:00.000"
/* Orignal query */
SELECT t.*
FROM dbo.telegram AS t
WHERE begin_ts <= CAST('$(end_ts)' AS DATETIME2(3))
AND end_ts >= CAST('$(begin_ts)' AS DATETIME2(3))
ORDER BY
id;
GO
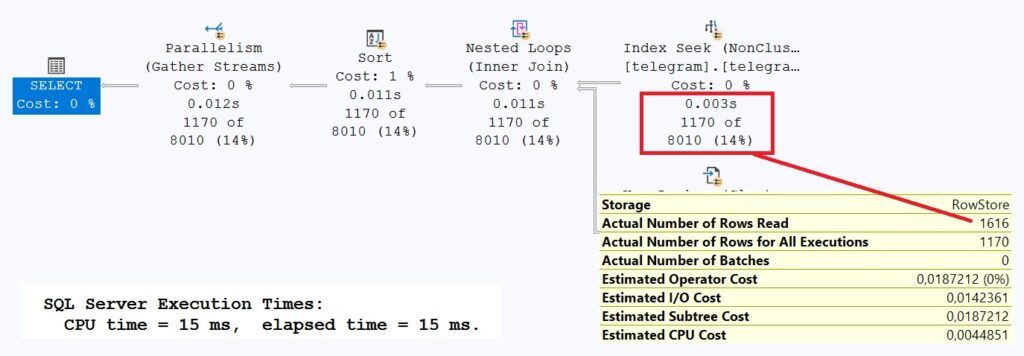
Although we now receive significantly more records, the query performs significantly better at 15ms. Once again, the [telegram_end_ts_begin_ts] index is responsible for the performance. This time, SQL Server had to search at the end of the index, thus skipping most of the rows in the index.
/* This statement must run in SQLCMD modus! */
:SETVAR begin_ts "2025-05-12 12:15:00.000"
:SETVAR end_ts "2025-05-12 12:45:00.000"
/* Optimized query */
SELECT t.*
FROM dbo.telegram AS t
INNER JOIN
(
SELECT id
FROM dbo.get_interval_id
(
'$(begin_ts)',
'$(end_ts)'
)
) AS gii
ON (t.id = gii.id)
WHERE (
t.begin_ts <= '$(end_ts)'
AND t.end_ts >= '$(begin_ts)'
)
ORDER BY
t.id;
GO
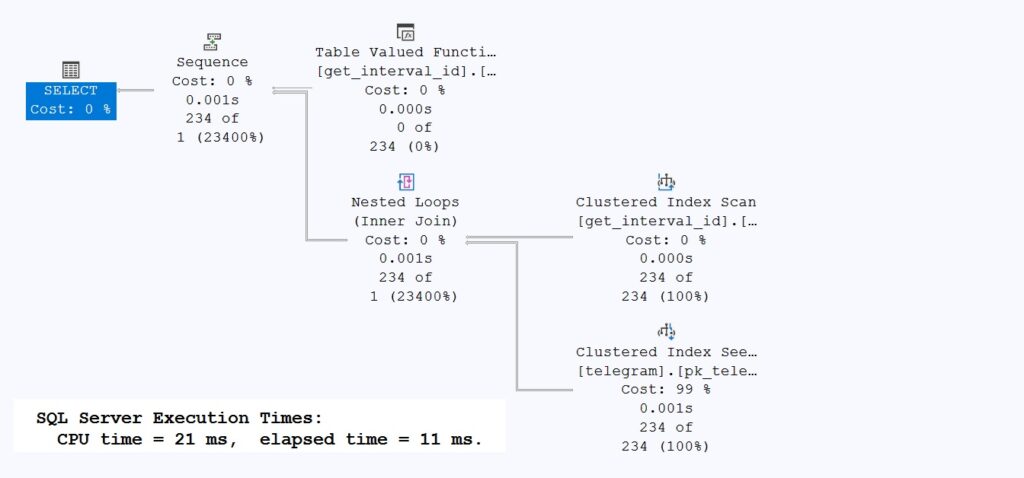
The runtime improvements are enormous. Not only does Microsoft SQL Server no longer need to parallelize due to the reduced costs, but runtime and IO have also decreased significantly.
However, I would like to draw your attention to the function’s estimated rows. Microsoft SQL Server has calculated the exact number of rows—a feature that has only been available since SQL Server 2017 (EE). The technique is called “interleaved execution”!
Please believe me that it is also very quick with the second search at the end of the data!
As long as we only return small amounts of data, the query performs very well. But how does the query behave when we receive more than 100,000 records? This is quite possible, since, for example, thousands of processes were already started before the desired time window or were started within the time window. The following example query illustrates the dilemma of the solution for large amounts of data!
/* This statement must run in SQLCMD modus! */
:SETVAR begin_ts "2025-05-26 12:00:00.000"
:SETVAR end_ts "2025-05-26 13:00:00.000"
/* Optimized query */
SELECT t.*
FROM dbo.telegram AS t
INNER JOIN
(
SELECT id
FROM dbo.get_interval_id
(
'$(begin_ts)',
'$(end_ts)'
)
) AS gii
ON (t.id = gii.id)
WHERE (
t.begin_ts <= '$(end_ts)'
AND t.end_ts >= '$(begin_ts)'
)
ORDER BY
t.id;
GO
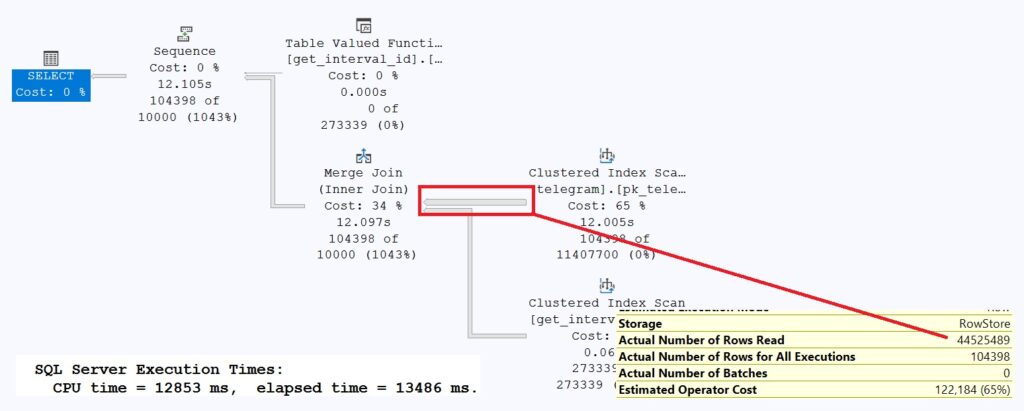
The execution plan reveals that SQL Server first scans the [dbo].[telegram] table for the EXACT values (SCAN) and then compares them with the function’s result set. This behavior is due to the fact that SQL Server estimated an extremely high number of records for the specified time interval. It’s obvious that a SCAN can retrieve the data faster than a dedicated SEEK after the function is executed. This issue was already discussed above—estimating time intervals isn’t always SQL Server’s strong suit.
How can Microsoft SQL Server be made to always execute the function first? By not allowing it to recalculate the estimated records using interleaved execution. Before Microsoft SQL Server 2017, a multi-statement user function could estimate a maximum of 100 records (1 in Microsoft SQL Server <= 2012). However, we’re taking advantage of this circumstance—maligned by many (including me)—here!
/* Disable interleaved execution for MSTVF! */
ALTER DATABASE SCOPED CONFIGURATION SET INTERLEAVED_EXECUTION_TVF = OFF;
GO
/* This statement must run in SQLCMD modus! */
:SETVAR begin_ts "2025-05-26 12:00:00.000"
:SETVAR end_ts "2025-05-26 13:00:00.000"
/* Optimized query */
SELECT t.*
FROM dbo.telegram AS t
INNER JOIN
(
SELECT id
FROM dbo.get_interval_id
(
'$(begin_ts)',
'$(end_ts)'
)
) AS gii
ON (t.id = gii.id)
WHERE (
t.begin_ts <= '$(end_ts)'
AND t.end_ts >= '$(begin_ts)'
)
ORDER BY
t.id;
GO
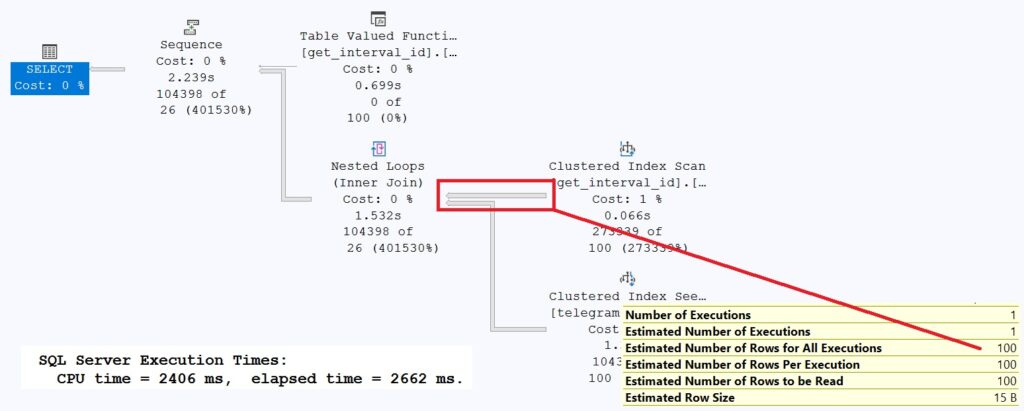
The feature “Interleaved Execution” is an Enterprise Feature. Since not all customers of the software work with an Enterprise Edition, it is important to ensure that the query also runs efficiently in a Standard Edition.
In this specific example, however, it is the other way around; the query would have run more efficiently in the Standard Edition than in the Enterprise Edition.
Final Thoughts
I would like to thank all of you for taking on this challenge. This challenge is certainly one of the most difficult. Whoever finds this solution can call themselves an “experienced DBA.” So many specifics played an important role here that aren’t immediately clear to everyone. But be prepared for the fact that the role of a DBA involves more than just backup/restore, but may also involve ideas for solving problems for your customers.
Thank you very much for participating and for reading!
Links to further topics
- Static relational interval trees: https://www.itprotoday.com/sql-server/interval-queries-in-sql-server
- User Definied Functions: https://learn.microsoft.com/en-us/sql/relational-databases/user-defined-functions/user-defined-functions
- Multi Statement Table Valued Function: https://learn.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql
- Inline Table Valued Function: https://learn.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql
- Interleaved Execution for Multi Statement Table Valued Functions: https://techcommunity.microsoft.com/blog/sqlserver/introducing-interleaved-execution-for-multi-statement-table-valued-functions/385417

