
Problem Description / Requirement
Your customer is using new software in the company. This software uses its own logic for protocol measures and locks because – presumably – the concept of intelligent locking is not known.
Before each query is called, the name of the object used, along with the time stamp and user name, is entered in the [dbo].[locks] table. As soon as the process is finished, the entry is removed again. The customer notices that after about 1 hour, access to the [dbo].[locks] table becomes so slow that the application shows noticeable failure symptoms.
Challenge
The customer contacts you for a root cause analysis of the behavior because the manufacturer has no explanation for it. Your task is:
- to work out a solution to maintain consistent performance.
- to find out why the performance on the table is continuously decreasing although only a few records are stored..
Solution
Step 1: Root Cause Analysis
The problem analysis is a bit tricky. When the stored procedure dbo.SQLQueryStress_stress_test is executed with SQL Query Stress, you quickly notice that the IO is constantly increasing. More IO means longer runtime.
If the runtime of a query is slowed down due to IO, only two aspects can come into play that explain this behavior:
- New records are constantly being added
- The version store for the database is activated
New records
This option can be ruled out with great certainty, as the description of the workload states that ONE data record is temporarily entered per user per object, which is then deleted again after the query has been executed. The number of data records remains “stable and the same”!
Activated Version Store
The Version Store in Microsoft SQL Server is a critical component used in managing row versioning for transactions. It operates within the TempDB database and stores previous versions of rows that have been modified by transactions. This allows SQL Server to support features like snapshot isolation and read-committed snapshot isolation (RCSI).
- When a transaction modifies a row, the original version of the row is copied to the Version Store before the change is committed.
- Other transactions that need to access the original data (e.g., for consistent reads or isolation) can retrieve it from the Version Store.
- The Version Store ensures that readers are not blocked by writers, improving concurrency and performance.
However, the Version Store can grow significantly in size, especially in systems with high transaction volumes or long-running queries.
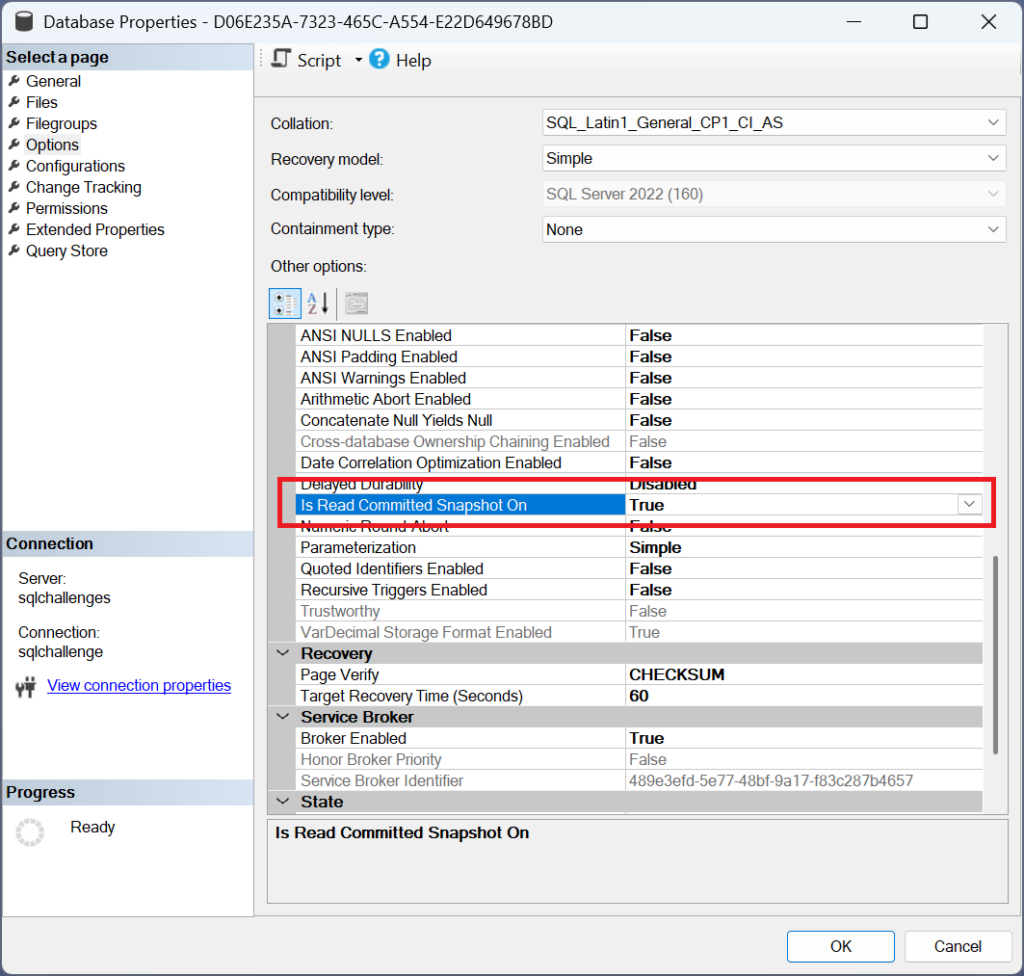
When the scenario was designed for you, “Read Committed Snapshot Isolation” was activated for the database, among other things.
The manufacturer hopes that the use of RCSI will improve the scalability of its application, since with RCSI, reading processes are no longer blocked by writing processes.
More Information about RCSI:
Step 2: Analysis of Stored Procedure [dbo].[SQLQueryStress_stress_test]
To simulate the customer’s workload, a stored procedure was implemented that adds new records at short intervals and then deletes them again after a short time (0.5 seconds). This is intended to simulate a workload that reflects the frequent access to different objects.
CREATE OR ALTER PROCEDURE [dbo].[SQLQueryStress_stress_test]
@table_name NVARCHAR(128)
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
DECLARE @version_store_mb BIGINT = 0;
BEGIN TRANSACTION;
DELETE dbo.locks
WHERE UPPER(table_name) = @table_name
AND locked_by = SUSER_SNAME();
WAITFOR DELAY '00:00:00.500';
INSERT INTO dbo.locks
(table_name, date_locked, application, locked_by)
VALUES
(@table_name, GETDATE(), APP_NAME(), SUSER_SNAME());
COMMIT TRANSACTION
END
It is noticeable that the query for deleting an existing record uses a NON Sargable WHERE clause. The UPPER() function does not allow the optimal use of a – possible – index. The entire table must ALWAYS be scanned! A look at the query store reveals the problem with this query.
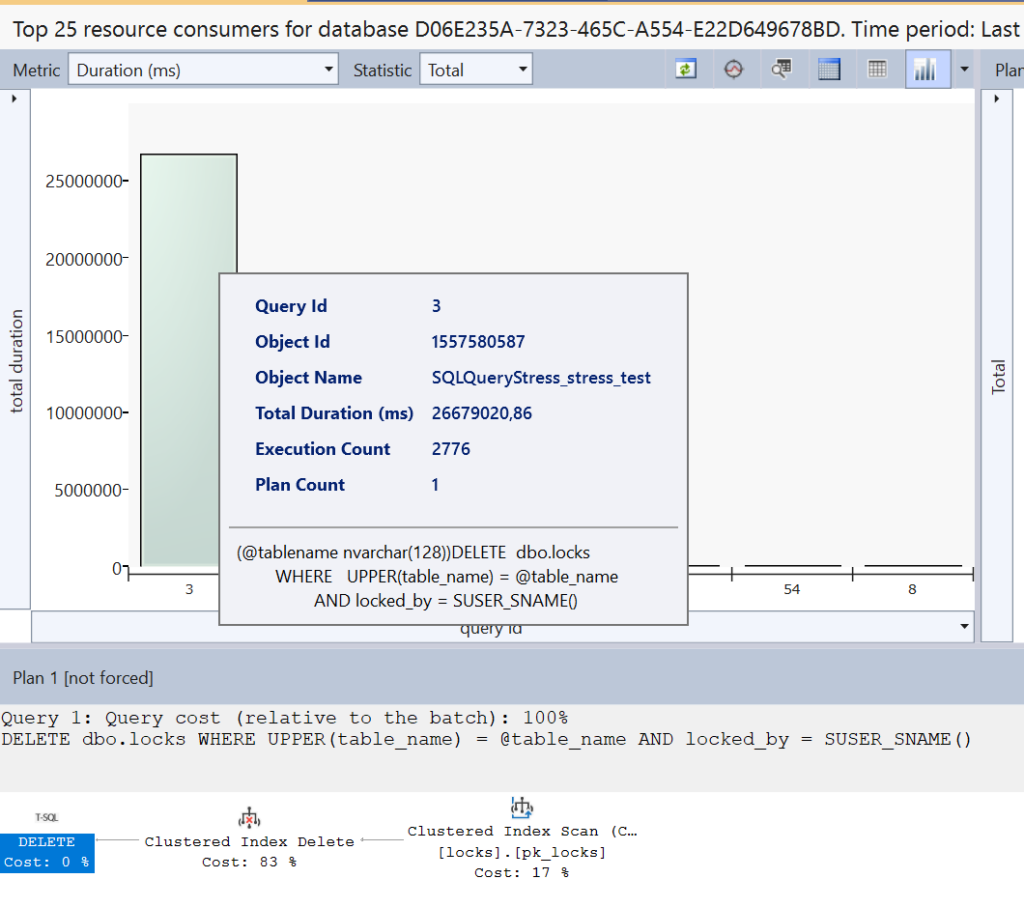
Step 3: Rewriting the code in the Stored Procedure
The challenge allows you to use your own indexes as well as manipulate the stored procedure code. For this reason, the query becomes SARGable by eliminating the UPPER() function from the code. In this case, this can be done without any problems, as the database collation is not case sensitive!
CREATE OR ALTER PROCEDURE [dbo].[SQLQueryStress_stress_test]
@table_name NVARCHAR(128)
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
DECLARE @version_store_mb BIGINT = 0;
BEGIN TRANSACTION;
DELETE dbo.locks
WHERE table_name = @table_name
AND locked_by = SUSER_SNAME();
WAITFOR DELAY '00:00:00.500';
INSERT INTO dbo.locks
(table_name, date_locked, application, locked_by)
VALUES
(@table_name, GETDATE(), APP_NAME(), SUSER_SNAME());
COMMIT TRANSACTION
END
GO
If you continue to run SQL Query Stress, you will find that the changes have had no effect. Microsoft SQL Server continues to use a FULL SCAN on the clustered index. So the next step is to check the implemented indexes.
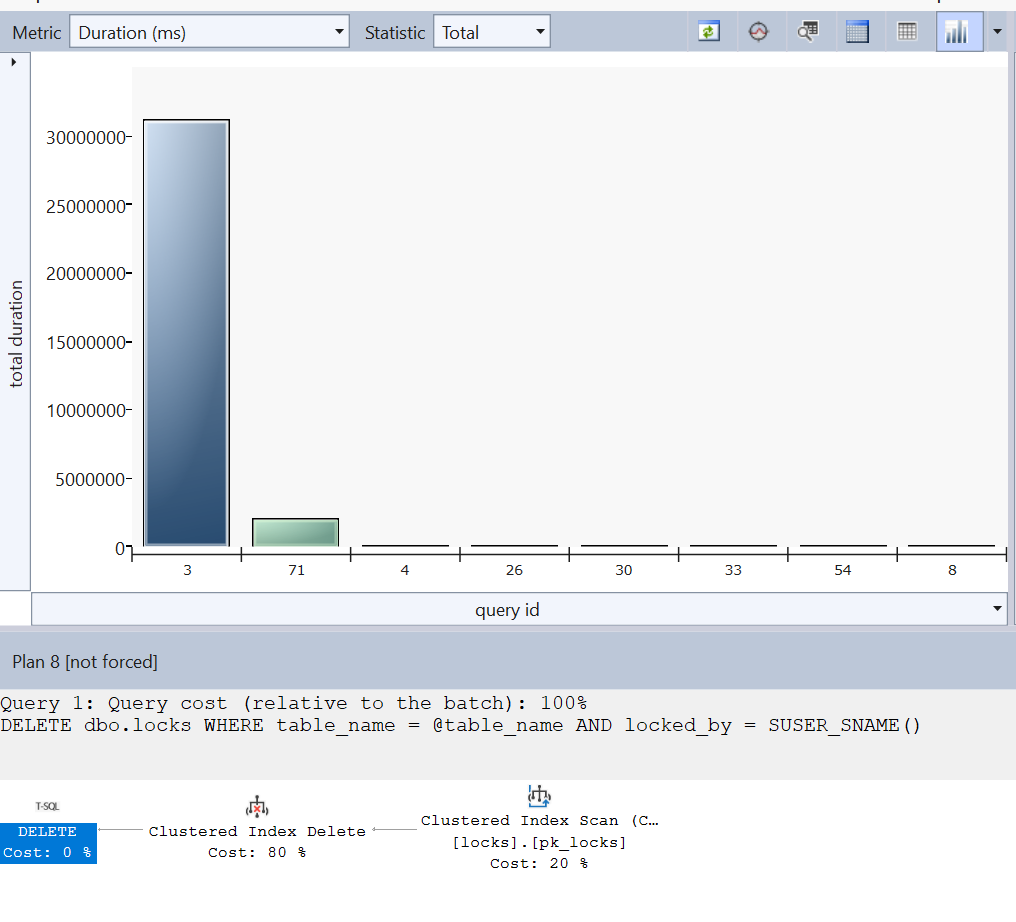
Step 4: Optimizing the indexes of the table [dbo].[locks]
The table [dbo].[locks] has two indexes. The clustered index is used for the primary key. Another – supporting – index is implemented for searching in the attribute [table_name].
/* Primary Key Constraint as clustered index */
ALTER TABLE [dbo].[locks] ADD CONSTRAINT [pk_locks] PRIMARY KEY CLUSTERED
(
[id] ASC,
[table_name] ASC
);
GO
/* additional supporting index */
CREATE UNIQUE NONCLUSTERED INDEX [unix_locks_tablename_id] ON [dbo].[locks]
(
[table_name] ASC,
[id] ASC
);
GO
As you can see, both indexes are useless for a table with a maximum of 200 records. The primary key (uniqueness) is even implemented incorrectly, because the attribute [Id] was defined as an IDENTITY column and thus has a unique selling point without including the attribute [table_name]!
The second – nonclustered – index only covers the [table_name] attribute. To further restrict the user name, Microsoft SQL Server would have to perform a key lookup, which is simply ignored for this small table. For this reason, this index is NEVER used!
What is missing is an effective unique index that specifically searches for the combination of [table_name] and [locked_by]. Since only one user can use an object in the database at the same time, this index can be unique. Contrary to my firm belief that a clustered index should be as small as possible and not changeable, an exception can be made here to avoid writing to two indexes.
/* Dropping the useless index */
DROP INDEX [unix_locks_tablename_id] ON [dbo].[locks];
GO
/* Dropping the existing clustered PRIMARY KEY */
ALTER TABLE dbo.locks DROP CONSTRAINT pk_locks;
GO
/* Creating a clustered PRIMARY KEY to cover the predicates */
ALTER TABLE [dbo].[locks] ADD CONSTRAINT [pk_locks] PRIMARY KEY CLUSTERED
(
[table_name] ASC,
[locked_by]
);
GO
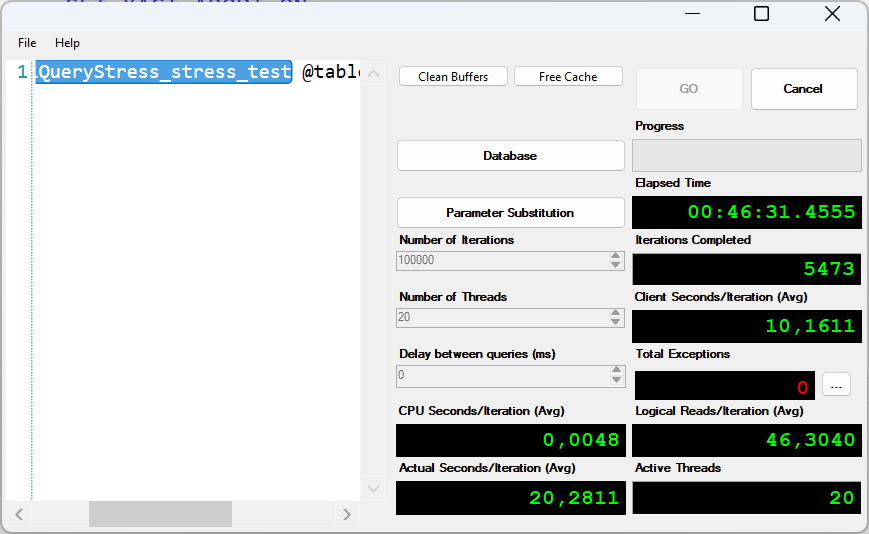
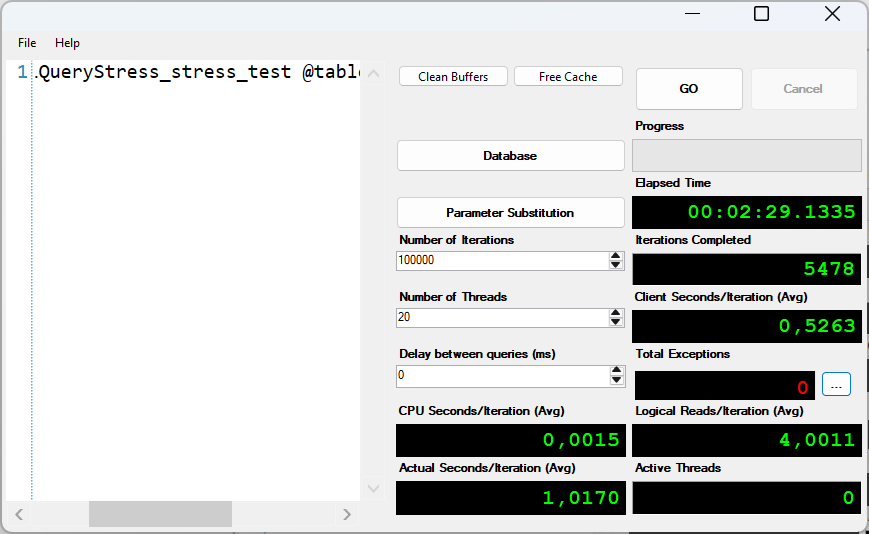
The difference after the revision is significant. Not only are the accesses to the version store constant and the avoided SCAN means that a complete search no longer has to be carried out, but the use of a more efficient index also results in a significant improvement in performance overall.
While average times of 10 seconds were the norm before the implementation, transactions are now processed within a few milliseconds.

