
Problem Description / Requirement
The software manufacturer’s database uses the [SQL_Latin1_General_CP1_CI_AS] collation for the application. The development team wrote a custom function that can be used to find customers based on an address search. The department had requested that the search must be case sensitive.
The development team created a User Defined Function dbo.get_customer_address() for the business to find addresses with case sensitive conditions.
Code of the User Defined Function
CREATE OR ALTER FUNCTION dbo.get_customer_address(@address VARCHAR(40))
RETURNS TABLE
AS
RETURN
(
SELECT *
FROM dbo.customers
WHERE c_address LIKE @address + '%' COLLATE Latin1_General_100_BIN
);
GO
The business is not satisfied with the performance when using the User Defined Function. They complain that even searching for a single customer takes a long time.
Solution
An experienced developer will immediately see that the collation for the search term is determined using an “explicit” label. Explicit labels take precedence over the implicit label of the left expression.
This means that the attribute in which the search term is searched must first be converted to the same collation.
We have the problem of a NONSargable query. Microsoft SQL Server will always have to perform a FULL SCAN on the table/index for the search.
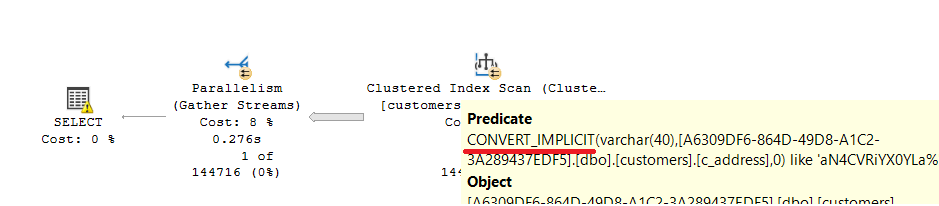
The FULL SCAN on the clustered index is performed despite an index on the [c_address] attribute, since a targeted search cannot be performed due to an implicit conversion.
For cost reasons, the query is parallelized and the warning for the SELECT operator indicates the conversion problem.
One way to optimize is to first search for the search term regardless of upper and lower case. This significantly reduces the number of results that must then be compared.
The most clever way to do this is to use a CTE in the function. This saves us from having to create additional objects.
CREATE OR ALTER FUNCTION dbo.get_customer_address(@address VARCHAR(40))
RETURNS TABLE
AS
RETURN
(
WITH l
AS
(
SELECT *
FROM dbo.customers
WHERE c_address LIKE @address + '%'
)
SELECT *
FROM l
WHERE c_address LIKE @address + '%' COLLATE Latin1_General_100_BIN
);
GO
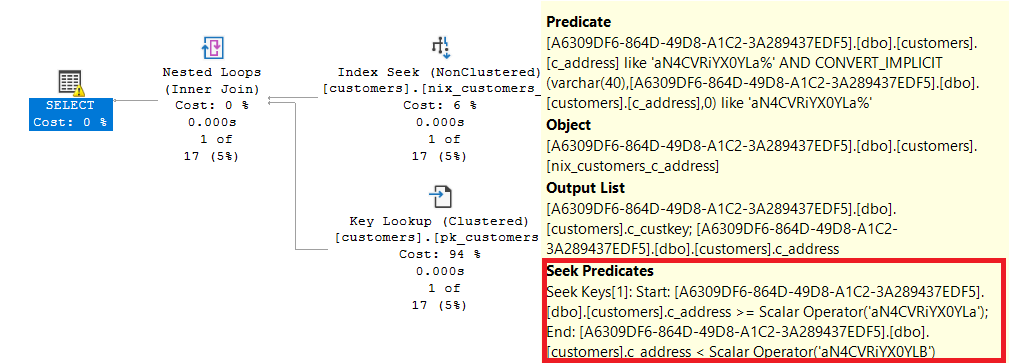
The execution phase is simple:
First, the SEEK operator is used to get only a subset of the data.
Then, the remaining rowset is searched for the values using a FILTER operation, which is case sensitive.
Alternative Solutions by Authors
Thank you very much for submitting your wonderful and interesting solutions:
- Henrik Staun Poulsen
- Damir Matesic
- Art
- Seba
Henrik Staun Poulsen and Damir Matesic
Both submitted an interesting solution by covering the transformation problem in a view. This is a valid solution and will help to improve the performance significantly.
Special thanks goes to Art who did it exactly the same way as I did with my solution.
/*
Let's create a view with the c_address transformed
with the correct collation
*/
CREATE OR ALTER VIEW dbo.MyUserView
WITH SCHEMABINDING
AS
SELECT u.c_custkey
, u.c_mktsegment
, u.c_nationkey
, u.c_name
, u.c_address
, u.c_phone
, u.c_acctbal
, u.c_comment
, address = CAST(u.c_address AS VARCHAR(40)) COLLATE Latin1_General_100_BIN
FROM dbo.customers u
GO
CREATE UNIQUE CLUSTERED INDEX ix_cl ON dbo.MyUserView (c_custkey) WITH (DATA_COMPRESSION=PAGE)
CREATE nonCLUSTERED INDEX ix_ncl ON dbo.MyUserView (address) WITH (DATA_COMPRESSION=PAGE)
GO
CREATE OR ALTER FUNCTION dbo.get_customer_address_Via_MyView(@address VARCHAR(40))
RETURNS TABLE
AS
RETURN
(
SELECT *
FROM dbo.MyUserView WITH (NOEXPAND, INDEX=ix_ncl)
WHERE address LIKE @address + '%' COLLATE Latin1_General_100_BIN
);
GO
Thank you all for your valuable feedback. And look forward to the next challenges…
My special thanks go to Milos Radivojevic. I saw this cool solution when we met at Data Saturday Vienna 2025.
Thank you for reading

