
Problem Description / Requirement
The [dbo].[marketsegments] table serves as a reference table for the real names of a customer’s market segment. In the [dbo].[customers] table, the [id] of the reference table is stored in the [c_mktsegment] attribute, allowing the real name to be output using a JOIN.
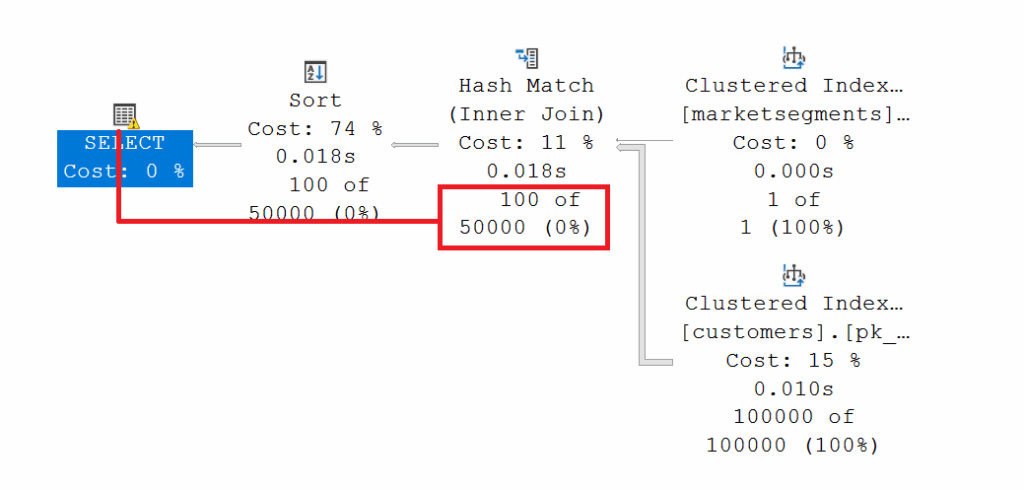
The following query was identified as a problem because it does not scale when searching for a market segment and allocates too much or too little memory for the sorting process, depending on the number of records found
/* Search for AUTOMOBILE */
SELECT c.c_custkey,
c.c_name,
m.m_mktsegment,
c.c_address
FROM dbo.customers AS c
INNER JOIN dbo.marketsegments AS m
ON (c.c_mktsegment = m.id)
WHERE m.m_mktsegment = 'AUTOMOBILE'
ORDER BY
c.c_name ASC
SELECT c.c_custkey,
c.c_name,
m.m_mktsegment,
c.c_address
FROM dbo.customers AS c
INNER JOIN dbo.marketsegments AS m
ON (c.c_mktsegment = m.id)
WHERE m.m_mktsegment = 'BUILDING'
ORDER BY
c.c_name ASC
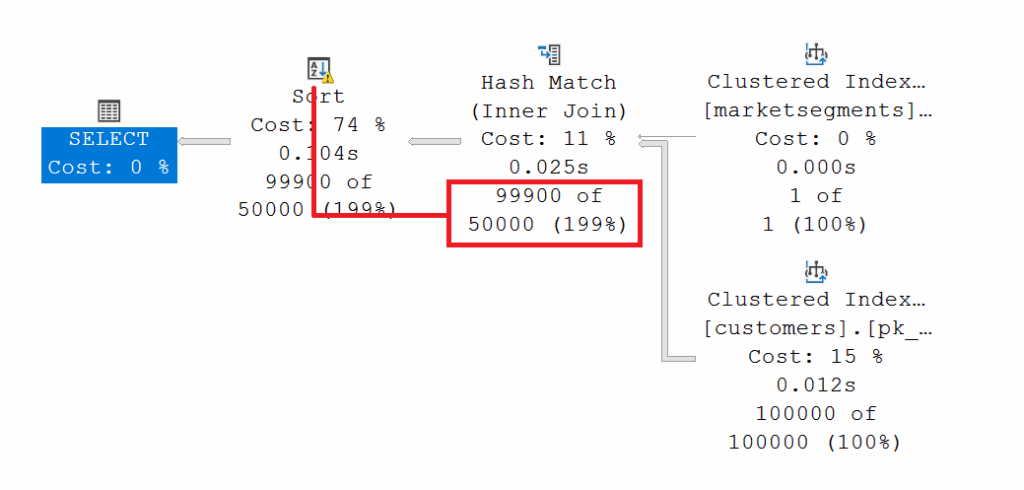
The figures clearly illustrate the problem. Although both execution plans indicate ideal index usage, SQL Server cannot correctly determine the estimated rows for the clustered index usage for [dbo][customers]. A look at the index statistics shows that they are current and accurate.
SELECT i.name,
h.step_number,
h.range_high_key,
h.range_rows,
h.equal_rows
FROM sys.indexes AS i
INNER JOIN sys.stats AS s
ON
(
i.object_id = s.object_id
AND i.index_id = s.stats_id
)
CROSS APPLY sys.dm_db_stats_histogram(s.object_id, s.stats_id) AS h
WHERE s.object_id = OBJECT_ID(N'dbo.customers', N'U')
AND i.name = N'nix_customers_c_mktsegment';

Challenge
The query must generate an ideal execution plan, regardless of the parameter value to be searched, that requests the resources depending on the expected data.
- The query itself may not be changed or rewritten.
- Custom indexes/statistics may be used.
- User database properties may be reconfigured.
Solution
Every time the query is executed—regardless of the search criteria—the query optimizer makes an error. It’s striking that both queries have identical “estimate rows.” These similarities suggest that the query optimizer isn’t taking the statistics for the [nix_customers_c_mktsegment] index into account. But this assumption is not correct as the XML representation of the execution plan shows.
<OptimizerStatsUsage>
<StatisticsInfo Database="[...]" Schema="[dbo]" Table="[customers]" Statistics="[_WA_Sys_00000003_4AB81AF0]" ... />
<StatisticsInfo Database="[...]" Schema="[dbo]" Table="[marketsegments]" Statistics="[_WA_Sys_00000002_48CFD27E]" ... />
<StatisticsInfo Database="[...]" Schema="[dbo]" Table="[marketsegments]" Statistics="[pk_marketsegments]" ... />
<StatisticsInfo Database="[...]" Schema="[dbo]" Table="[customers]" Statistics="[nix_customers_c_mktsegment]" ... />
</OptimizerStatsUsage>
Step 1: Root Cause Analysis
The question is, why can’t the query optimizer read the correct number of rows from the index histogram? If the queries aren’t executed via the [dbo].[marketsegments] table, but rather the [id] of the relevant market segments is queried directly, the query optimizer works as expected.
SELECT c.c_custkey,
c.c_name,
m.m_mktsegment,
c.c_address
FROM dbo.customers AS c
INNER JOIN dbo.marketsegments AS m
ON (c.c_mktsegment = m.id)
WHERE c.c_mktsegment = 1 /* AUTOMOBILE */
ORDER BY
c.c_name ASC;
SELECT c.c_custkey,
c.c_name,
m.m_mktsegment,
c.c_address
FROM dbo.customers AS c
INNER JOIN dbo.marketsegments AS m
ON (c.c_mktsegment = m.id)
WHERE c.c_mktsegment = 2 /* BUILDING */
ORDER BY
c.c_name ASC;
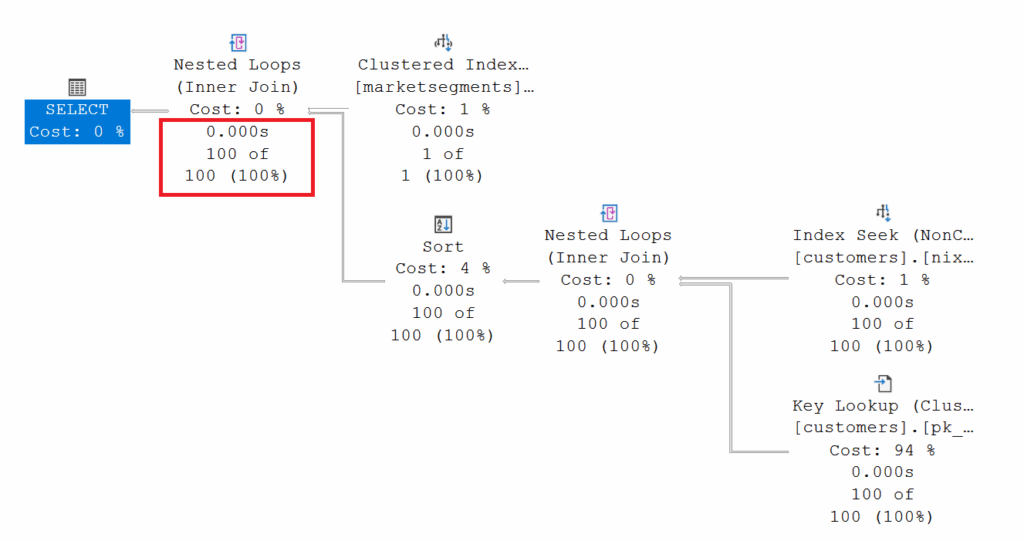
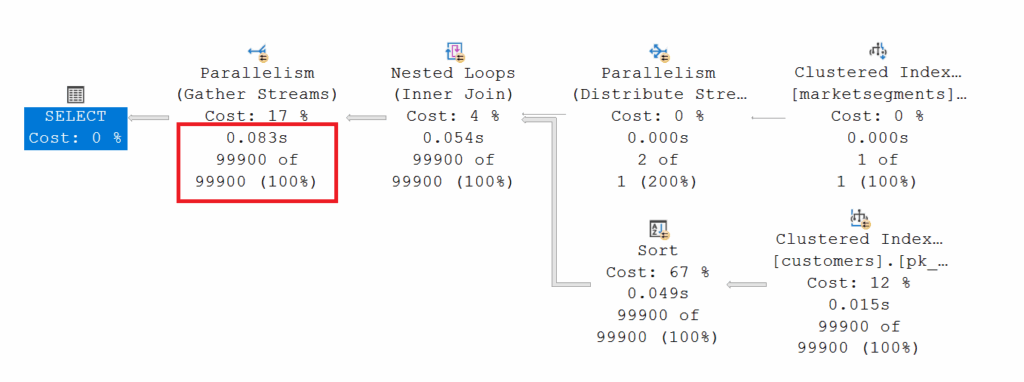
To understand why the Query Optimizer cannot correctly determine the “estimated rows,” we need to take a closer look at the value of the “estimated rows.” Both queries return exactly the same value. The [dbo].[customers] table contains 100,000 records with a reference value for a market segment. The Query Optimizer’s estimates cover exactly 50% of the total records! There are only two entries in the [dbo].[marketsegments] table. This allows us to derive a correlation between the number of records in [dbo].[customers] and the possible entries for [c_mktsegment]. The distribution rate is 50%. This distribution rate is also called a “density vector” in a statistics object in Microsoft SQL Server and can be output using DBCC SHOW_STATISTICS.
DBCC SHOW_STATISTICS (N'dbo.customers', N'nix_customers_c_mktsegment');
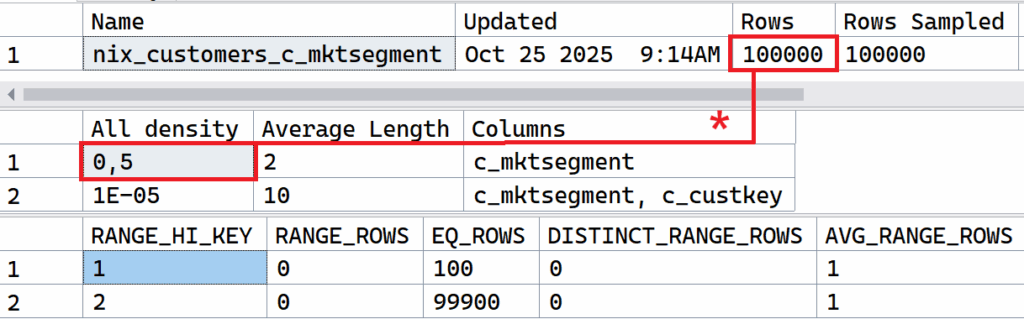
Why are the estimates be off?
The density vector of a statistics object is used by the query optimizer whenever it doesn’t have a specific value to search for in the histogram. If a value for c_mktsegment is used as a predicate—as shown in the example above—the query optimizer can use the histogram. Otherwise, only the density vector remains for determining “estimated rows”!
Let’s put ourselves in the optimizer’s shoes. At compile time, we only know the query value we’re looking for in the [dbo].[marketsegments] table (AUTOMOBILE, BUILDING). We don’t yet know the corresponding primary key value (which we’ll need later in [dbo].[customers]!) at compile time! Therefore, the query optimizer CANNOT use the histogram for the index [nix_customers_c_mktsegment] and must derive its estimates from the density vector (distribution: 50%).
Step 2: Finding an appropriate solution
The solution is to provide the query optimizer with more information to use during the compilation phase. The most important tool for the query optimizer is statistics. At compile time, the query optimizer only knows the market segment to be searched. So we give the query optimizer a dedicated statistics object for each market segment so that it can determine the corresponding Primary Key.
CREATE STATISTICS stats_marketsegment_automobile ON dbo.marketsegments (id) WHERE m_mktsegment = 'AUTOMOBILE';
CREATE STATISTICS stats_marketsegment_building ON dbo.marketsegments (id) WHERE m_mktsegment = 'BUILDING';
Once the manual statistics have been created, success is achieved because the Query Optimizer now knows the [id] that lies behind a search value.
Addendum
- In SQL Server, you cannot use filtered statistics in parameterized queries because the query optimizer does not know what concrete value the parameter will have at runtime when creating the execution plan — and therefore cannot decide whether a filtered statistic is relevant. In this case, the query would have to be executed with the RECOMPILE option.
- Of course, the same result can be achieved with a filtered index. But why keep an index in the database that needs to be maintained and updated? After all, an index uses a statistical object in the background!

